
Estimated reading time: 3 minutes
In einer Ära, in der Daten das wertvollste Kapital eines Unternehmens darstellen, ist dabei jede ungeplante Ausfallzeit gleichbedeutend mit massivem wirtschaftlichem Schaden. Eine Cloud-Disaster-Recovery-Strategie – wobei diese oft als Disaster Recovery as a Service (DRaaS) bezeichnet wird – gilt heute als Goldstandard für IT-Resilienz. Anstatt sich ausschließlich auf lokale Backups zu verlassen, ermöglicht die Cloud die spiegelverkehrte Vorhaltung kritischer IT-Systeme in einer externen, hochverfügbaren Umgebung. Auf diese Weise garantiert sie die Business Continuity, selbst wenn das eigene Rechenzentrum durch Ransomware, Hardware-Defekte oder Naturereignisse kompromittiert ist. Zudem reduziert eine Cloud-DR-Strategie die Wiederherstellungszeiten drastisch und sorgt dafür, dass der Geschäftsbetrieb auch im Krisenfall aufrechterhalten bleibt.
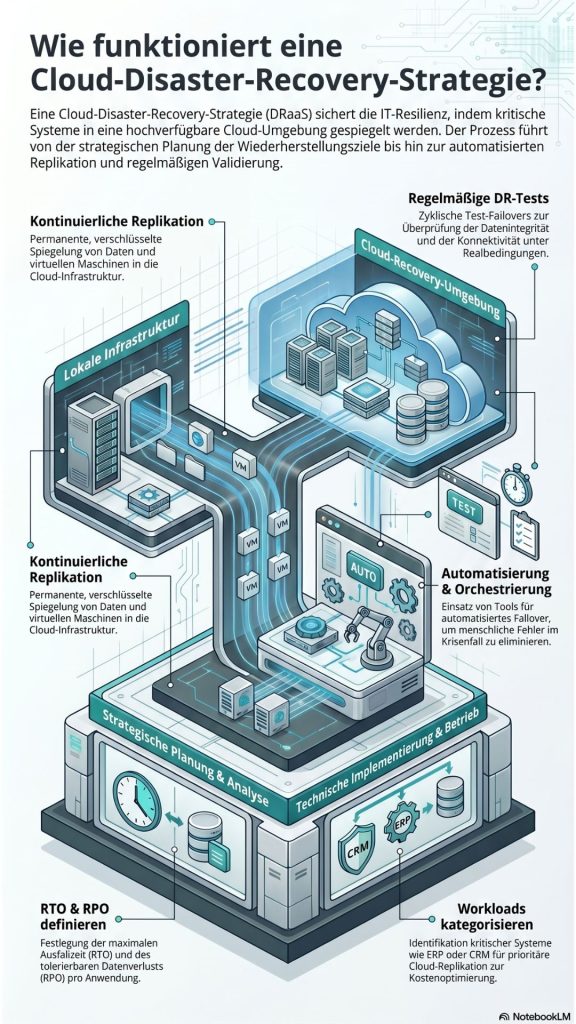
Die folgende Checkliste erläutert dabei in fünf essenziellen Schritten, wie Sie eine solche Strategie effektiv konzipieren sowie implementieren.
Checkliste: In 5 Schritten zur Cloud-Disaster-Recovery-Strategie #
Folgen Sie diesen fünf Schritten:
- Definition von RTO und RPO
Analysieren Sie Ihre geschäftskritischen Workloads. Definieren Sie für jede Anwendung das Recovery Time Objective (RTO – wie lange darf der Ausfall dauern?) und das Recovery Point Objective (RPO – wie viel Datenverlust ist tolerierbar?). Diese Kennzahlen bilden das Fundament für die gesamte Strategie.
- Identifikation der Workloads
Nicht jedes System benötigt eine Echtzeit-Replikation in die Cloud. Kategorisieren Sie Ihre Anwendungen. Kritische Systeme (ERP, CRM) benötigen DRaaS, während weniger zeitkritische Daten eventuell mit standardisierten Backup-Lösungen abgesichert werden können. Dies optimiert Ihre Kosten.
- Einrichtung der kontinuierlichen Replikation
Implementieren Sie eine Lösung, die Ihre Daten und virtuellen Maschinen kontinuierlich in die Cloud repliziert. Achten Sie auf Bandbreitenoptimierung und eine sichere Verschlüsselung des Datenstroms während der Übertragung und im Ruhezustand (at rest).
- Automatisierung durch Orchestrierung
Im Krisenfall zählt jede Sekunde. Nutzen Sie Disaster-Recovery-Orchestration-Tools, die das Failover-Szenario automatisieren. Dies minimiert menschliche Fehler bei der Umschaltung auf die Cloud-Infrastruktur und beschleunigt den Wiederanlaufprozess massiv.
- Regelmäßige DR-Tests
Ein Disaster-Recovery-Plan, der nie getestet wurde, existiert nicht. Führen Sie in definierten Intervallen Test-Failovers durch, um die Integrität der Daten und die Konnektivität der Dienste in der Cloud-Umgebung zu verifizieren.
Sie suchen einen verlässlichen Cloud-Disaster-Recovery Partner? #
Der Aufbau einer Cloud-Disaster-Recovery-Strategie ist eine komplexe architektonische Aufgabe, die tiefes Know-how erfordert. Ein falsch konfiguriertes Failover kann im Ernstfall wertvolle Zeit kosten oder zu Dateninkonsistenzen führen. Vertrauen Sie auf Experten, die moderne Cloud-Infrastrukturen und DRaaS-Konzepte beherrschen.
Wir unterstützen Sie dabei, Ihre IT-Umgebung krisenfest zu machen und eine skalierbare Disaster-Recovery-Lösung zu etablieren, die Ihre Geschäftskontinuität garantiert.
Erfahren Sie mehr über unsere Cloud-Disaster-Recovery-Lösungen.

